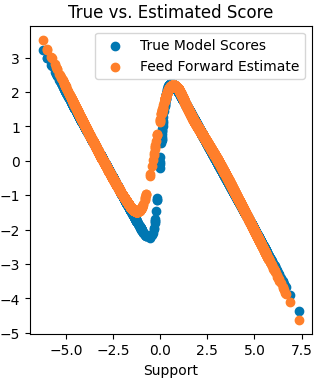
Trains score-based generative models on hand-crafted 1D distributions — a minimal setting that makes the math transparent. Built entirely in JAX with Flax.
Key ideas covered:
- Score matching: learning ∇log p(x) without computing the partition function
- Denoising score matching: the practical training objective via noise perturbations
- Langevin dynamics: sampling from the learned score using stochastic gradient ascent
- Connection to diffusion: how iterative denoising emerges from score estimation